
Transformer核心架构
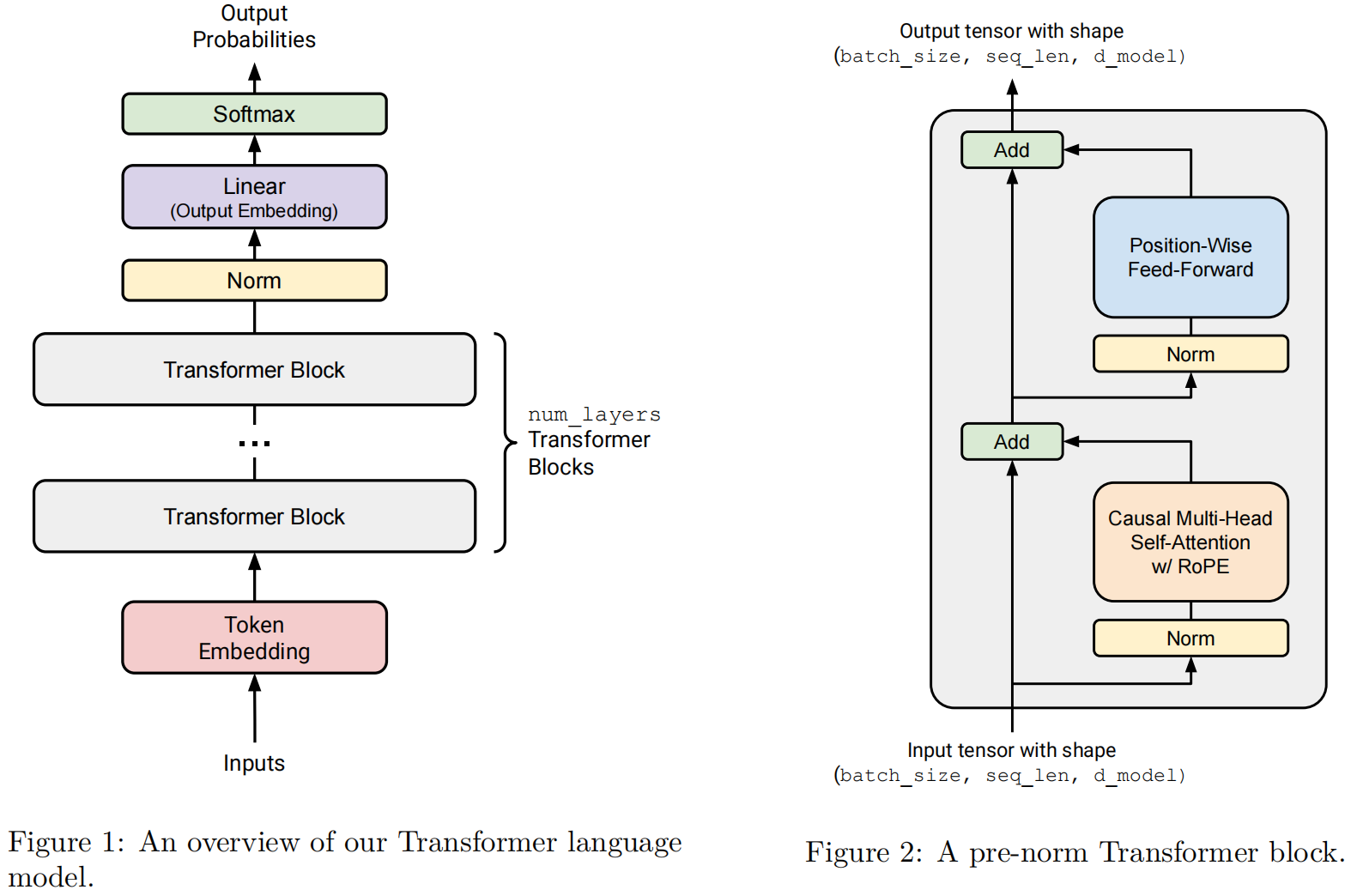
1. 总览
Transformer 模型基于 多头自注意力 和 前馈网络 堆叠而成。常用结构有编码器+解码器(Encoder+Decoder),只编码器(Encoder-only),只解码器(Decoder-only)。目前市面上性能最强的大模型基本都采用的是Decoder-only:
任务统一:只做一件事 → 预测下一个 token。
结构简单:不用 encoder / cross-attention。
好扩展:数据、参数、算力一放大 → 效果直接提升。
而编解码结构涉及到,输入一段,输出另一段,并计算交叉注意力等等,结构太复杂。
整体数据流:
Token IDs (B, T) → Embedding (B, T, D) → 位置编码 (RoPE) → N × DecoderBlock → LM Head → Logits (B, T, V)
其中:
B= batch sizeT= 序列长度D= 模型维度(d_model)V= 词表大小
每个 DecoderBlock 包含:多头自注意力(带因果 mask)
前馈网络
残差连接 & 层归一化(RMSNorm)
2. 嵌入与位置编码
2.1 Token Embedding
2.1.1 是什么
Token Embedding的主要任务是,给词表里的每一个Token ID 分配一个 长度为D(d_model)的浮点数向量。
2.1.2 为什么
在 ID 空间里,编号10和编号11的词(使用bpe编码器或者其他编码器) 可能并没有实际联系。 但是在向量空间里面,我们可以计算两个词之间的欧氏距离或者其他方式,来计算他们之间的语义相似性。因此,使用embedding层,赋予了模型处理语义相似性的能力。
2.1.3 怎么做
Embedding的数据流是 Token IDs (B, T) → Embedding (B, T, D),这显然不是一个矩阵乘法。其本质是:查表,等价于 one-hot × 矩阵。
Token IDs (B, T)
↓
Embedding matrix 查表(不是普通矩阵乘法)
↓
(B, T, D)
Embedding Matrix: (V, D):
V = vocab size(词表大小)
D = hidden dim(比如 768 / 4096)
计算示例如下:
input ids: (B, T) # 这里应该理解为,索引。
[ [5, 20, 13],
[7, 2, 99] ]
上述一共6个id,我们要做的是embedding[id] → (B, T, D)
也就是说,我们要维护一个(V,D)维度的矩阵,矩阵参数参与模型训练,通过反向传播来更新。
2.1.4 softmax 共享权重
数据流向:
输入侧 输出侧
┌─────────────────┐ ┌────────────────────┐
│ Token IDs │ │ Hidden States │
│ (B, T) │ │ (B, T, D) │
└────────┬────────┘ └─────────┬──────────┘
↓ ↓
Embedding Matrix W Linear(输出层)
(V, D) (D, V)
↓ ↓
(B, T, D) (B, T, V)
↓
Softmax
推导:
输出层权重 = W^T # 换成转置表示
(D, V) = (V, D)^T
变为hidden_state · W^T
对于单个Token:
h ∈ (D,)
W ∈ (V, D)
logits = h · W^T # h是当前语义,这一步计算了和所有词的相似度(还没softmax之前的值)
score_i = h · W[i] # i ∈ [0, vocab_size - 1]
W[i] = 第 i 个 token 的 embedding # 豁然开朗了,联系上一行的点积操作
W可以拿去做embedding的权重
这样思考的话,其实是减少了一个W的训练,减少了需要训练的参数,同时保证了双端的语义一致性(权重都一样了)。早期bert等采用此方法能减少训练资源,并且实验结果显示更好。
目前大模型时代,随着参数量提升,embedding所占的权重下降,并且可能会引发一些其他问题,基本上已经不采用了。
拓展链接:
https://kexue.fm/archives/9698
2.1.5 代码实现
class Embedding(nn.Module):
'''
一个最简版的 embedding 层实现:
功能:
- 输入:token ids(整数索引)[B, S]
- 输出:对应的向量表示 [B, S, D]
本质:
- 维护一个可训练参数矩阵 W ∈ (vocab_size, embedding_dim)
- forward 时做的是“查表”(index lookup),不是矩阵乘法
'''
def __init__(self, num_embeddings: int, embedding_dim: int, device=None, dtype=None):
super().__init__()
# nn.Module:
# - PyTorch 所有“层”的基类
# - 提供参数管理、自动求导、.to(device) 等能力
# factory_kwargs:
# - 用于统一控制张量创建时的 device / dtype(比如 GPU / float16)
factory_kwargs = {'device': device, 'dtype': dtype}
# nn.Parameter:
# - 把一个 tensor 注册为“模型参数”
# - 会被 optimizer 更新(requires_grad=True)
# - 会出现在 model.parameters() 里
self.weight = nn.Parameter(
torch.empty((num_embeddings, embedding_dim), **factory_kwargs)
)
# torch.empty:
# - 只分配内存,不初始化(里面是随机垃圾值,效率高)
# - 这里形状是 (V, D),V=vocab_size
# nn.init.trunc_normal_:
# - 原地初始化(in-place)
# - 从截断正态分布采样:
# mean=0, std=1
# 截断范围 [-3, 3]
# - 目的:避免极端大值,训练更稳定
nn.init.trunc_normal_(self.weight, mean=0.0, std=1.0, a=-3.0, b=3.0)
def forward(self, token_ids: torch.Tensor) -> torch.Tensor:
# forward:
# - 定义前向计算逻辑
# - 被调用时:output = model(input)
# token_ids:
# - 形状: [B, S]
# - 每个元素是 int(0 ~ vocab_size-1)
# self.weight[token_ids]:
# - 这是 PyTorch 的“高级索引”(advanced indexing)
# - 等价于:对每个 id,取 weight 的第 id 行
# - 本质就是 embedding lookup(查表)
# 举例:
# weight.shape = (V, D)
# token_ids = [[5, 20]]
# → 输出 = [weight[5], weight[20]]
# 输出形状:
# [B, S, D]
return self.weight[token_ids]
2.2 位置编码
2.2.1 为什么
虽然Transformer实现了并行计算,加快了运行速度,但是相比于传统的rnn等,transformer本身并不具备序列信息,因此需要添加位置编码。(例如,I love you 和 you love I 语义天差地别,而如果没有位置编码的话,模型并不能很好的区分)。
2.2.2 原理
RoPE实际上是一个非常巧妙的设计,与矩阵乘法结合,利用三角函数的性质,使得可以通过乘法结果来表示相对序列关系。
设隐藏层维度为d,位置索引为m 对应的查询向量为q_m。将q_m按两两一组分成d/2对:
对第组
其中i为索引,10000是基频,d是维度:
不同维度d的旋转速度不一样,这样实现了了对局部和全局序列关系的捕捉。
旋转后的查询向量在第i组为:
对键向量同样处理。则注意力分数中的内积满足:
即 内积只与相对位置m−n 有关,实现了相对位置编码。
更加详细的论述参考下列文章:
LLM学习记录(五)--超简单的RoPE理解方式 - 知乎
Transformer升级之路:10、RoPE是一种β进制编码 - 科学空间|Scientific Spaces
2.2.3 工程实现
经过RoPE的序列如下:
显然,旋转矩阵是一个稀疏矩阵,直接进行矩阵乘法显然是非常不合理的。
我们做如下等价计算:
图中计算符号为克罗内克积:就是“用第一个矩阵的每个元素乘以第二个矩阵整体”,结果是一个超大矩阵。
2.2.4 Pytorch的广播机制
Python
"""
======================== PyTorch 广播机制说明(RoPE 相关)========================
PyTorch 的广播(broadcasting)用于在不同形状的 tensor 之间做逐元素运算时,
自动扩展“维度为 1”的轴,使两个 tensor 形状对齐,而无需显式 repeat/expand。
📌 核心规则(非常重要):
从“右往左”对齐两个 tensor 的维度:
1. 如果两个维度相等 → 可以直接计算
2. 如果其中一个维度是 1 → 自动扩展成另一个维度大小(广播)
3. 如果维度不同且都不为 1 → 报错
================================================================================
📌 RoPE 场景中的典型张量形状
================================================================================
假设:
x 的形状为:
x: (B, H, S, D)
其中:
- B = batch size
- H = attention heads
- S = sequence length
- D = head dimension(必须是偶数)
RoPE 会拆分为:
x_even: (B, H, S, D/2)
x_odd: (B, H, S, D/2)
位置编码 cos/sin 初始形状为:
cos: (B, S, D/2)
sin: (B, S, D/2)
================================================================================
📌 为什么需要 unsqueeze?
================================================================================
为了让 cos/sin 能和 x_even 对齐,需要插入 head 维:
cos.unsqueeze(1)
sin.unsqueeze(1)
变为:
cos: (B, 1, S, D/2)
sin: (B, 1, S, D/2)
================================================================================
📌 广播如何发生(关键)
================================================================================
进行运算:
x_even * cos
对齐维度:
x_even: (B, H, S, D/2)
cos: (B, 1, S, D/2)
从右往左对齐:
dim -1: D/2 vs D/2 → OK
dim -2: S vs S → OK
dim -3: H vs 1 → 广播发生
👉 PyTorch 会自动把 cos 在 head 维复制 H 份:
cos (逻辑上变成):
(B, H, S, D/2)
⚠️ 注意:这个“扩展”是**逻辑上的,不是物理拷贝**,不会真正占用 H 倍内存。
================================================================================
📌 RoPE 中广播的本质作用
================================================================================
广播使得:
- 每个 head 使用同一组 sin/cos 位置编码
- 不需要为每个 head 单独计算 positional encoding
- 保持计算高效(避免显式 expand)
================================================================================
📌 总结一句话
================================================================================
PyTorch 广播 = 自动把“维度为 1”的轴扩展成匹配维度,使不同 shape 的 tensor
可以进行逐元素运算,而 RoPE 中主要利用它让 (B,1,S,D/2) 与 (B,H,S,D/2) 对齐。
"""
2.2.5 代码实现
Python
class RotaryPositionalEmbedding(nn.Module):
def __init__(self, theta: float, d_k: int, max_seq_len: int, device=None):
"""
初始化 RoPE 模块
theta: 基准频率 (通常为 10000)
d_k: 每个 Head 的维度 (必须是偶数)
max_seq_len: 最大序列长度
"""
super().__init__()
self.d_k = d_k
# 1. 计算频率 omega_k = theta^(-2k / d)
# 我们只需要计算 d_k/2 个频率, 因为旋转是成对进行的
# arange(0, d_k, 2) 产生 [0, 2, 4, ..., d_k-2], 对应公式中的2k-2(k从1开始)
powers = torch.arange(0, d_k, 2, device=device).float() / d_k
freqs = 1.0 / (theta ** powers) # 形状: (d_k/2,)
# 创建位置序列 [0,1,..., max_seq_len - 1]
t = torch.arange(max_seq_len, device=device).float() # 形状: (max_seq_len,)
# 3. 计算所有位置的所有角度 (外积)
# freqs_matrix 形状: (max_seq_len, d_k/2)
freqs_matrix = torch.outer(t, freqs)
# 4. 预计算 cos 和 sin 并作为 buffer 注册
# 使用 persistent=False 确保这些缓存不会被保存在 state_dict 中 (因为可以随时重新生成)
self.register_buffer("cos_cached", freqs_matrix.cos(), persistent=False)
self.register_buffer("sin_cached", freqs_matrix.sin(), persistent=False)
def forward(self, x: torch.Tensor, token_positions: torch.Tensor) -> torch.Tensor:
# 1. 提取 cos/sin (..., Seq, d_k/2)
cos = self.cos_cached[token_positions]
sin = self.sin_cached[token_positions]
# 2. 维度对齐
# 只有当 x 是 4D (含 Head 维) 且 cos 是 3D (含 Batch 维) 时, 才需要手动插入 Head 维。
# 对于 test_rope 这种 3D x vs 2D cos 的情况, PyTorch 会自动左侧补 1, 无需操作。
if x.ndim > cos.ndim and cos.ndim >= 3:
cos = cos.unsqueeze(1)
sin = sin.unsqueeze(1)
# 确保类型一致
cos = cos.to(x.dtype)
sin = sin.to(x.dtype)
# 3. 拆分
x_even = x[..., 0::2]
x_odd = x[..., 1::2]
output = torch.empty_like(x)
output[..., 0::2] = x_even * cos - x_odd * sin
output[..., 1::2] = x_even * sin + x_odd * cos
return output
3. 多头注意力(Multi-Head Attention)
3.1 缩放点积注意力
3.1.1 为什么
Attention的核心思想是让模型关注输入中重要的部分,忽略不重要的部分。
3.1.2 是什么
给定 Q, K, V(形状均为 (B, n_heads, T, d_k)),计算公式为:
"""
======================== PyTorch 广播机制说明(RoPE 相关)========================
PyTorch 的广播(broadcasting)用于在不同形状的 tensor 之间做逐元素运算时,
自动扩展“维度为 1”的轴,使两个 tensor 形状对齐,而无需显式 repeat/expand。
📌 核心规则(非常重要):
从“右往左”对齐两个 tensor 的维度:
1. 如果两个维度相等 → 可以直接计算
2. 如果其中一个维度是 1 → 自动扩展成另一个维度大小(广播)
3. 如果维度不同且都不为 1 → 报错
================================================================================
📌 RoPE 场景中的典型张量形状
================================================================================
假设:
x 的形状为:
x: (B, H, S, D)
其中:
- B = batch size
- H = attention heads
- S = sequence length
- D = head dimension(必须是偶数)
RoPE 会拆分为:
x_even: (B, H, S, D/2)
x_odd: (B, H, S, D/2)
位置编码 cos/sin 初始形状为:
cos: (B, S, D/2)
sin: (B, S, D/2)
================================================================================
📌 为什么需要 unsqueeze?
================================================================================
为了让 cos/sin 能和 x_even 对齐,需要插入 head 维:
cos.unsqueeze(1)
sin.unsqueeze(1)
变为:
cos: (B, 1, S, D/2)
sin: (B, 1, S, D/2)
================================================================================
📌 广播如何发生(关键)
================================================================================
进行运算:
x_even * cos
对齐维度:
x_even: (B, H, S, D/2)
cos: (B, 1, S, D/2)
从右往左对齐:
dim -1: D/2 vs D/2 → OK
dim -2: S vs S → OK
dim -3: H vs 1 → 广播发生
👉 PyTorch 会自动把 cos 在 head 维复制 H 份:
cos (逻辑上变成):
(B, H, S, D/2)
⚠️ 注意:这个“扩展”是**逻辑上的,不是物理拷贝**,不会真正占用 H 倍内存。
================================================================================
📌 RoPE 中广播的本质作用
================================================================================
广播使得:
- 每个 head 使用同一组 sin/cos 位置编码
- 不需要为每个 head 单独计算 positional encoding
- 保持计算高效(避免显式 expand)
================================================================================
📌 总结一句话
================================================================================
PyTorch 广播 = 自动把“维度为 1”的轴扩展成匹配维度,使不同 shape 的 tensor
可以进行逐元素运算,而 RoPE 中主要利用它让 (B,1,S,D/2) 与 (B,H,S,D/2) 对齐。
"""
2.2.5 代码实现
class RotaryPositionalEmbedding(nn.Module):
def __init__(self, theta: float, d_k: int, max_seq_len: int, device=None):
"""
初始化 RoPE 模块
theta: 基准频率 (通常为 10000)
d_k: 每个 Head 的维度 (必须是偶数)
max_seq_len: 最大序列长度
"""
super().__init__()
self.d_k = d_k
# 1. 计算频率 omega_k = theta^(-2k / d)
# 我们只需要计算 d_k/2 个频率, 因为旋转是成对进行的
# arange(0, d_k, 2) 产生 [0, 2, 4, ..., d_k-2], 对应公式中的2k-2(k从1开始)
powers = torch.arange(0, d_k, 2, device=device).float() / d_k
freqs = 1.0 / (theta ** powers) # 形状: (d_k/2,)
# 创建位置序列 [0,1,..., max_seq_len - 1]
t = torch.arange(max_seq_len, device=device).float() # 形状: (max_seq_len,)
# 3. 计算所有位置的所有角度 (外积)
# freqs_matrix 形状: (max_seq_len, d_k/2)
freqs_matrix = torch.outer(t, freqs)
# 4. 预计算 cos 和 sin 并作为 buffer 注册
# 使用 persistent=False 确保这些缓存不会被保存在 state_dict 中 (因为可以随时重新生成)
self.register_buffer("cos_cached", freqs_matrix.cos(), persistent=False)
self.register_buffer("sin_cached", freqs_matrix.sin(), persistent=False)
def forward(self, x: torch.Tensor, token_positions: torch.Tensor) -> torch.Tensor:
# 1. 提取 cos/sin (..., Seq, d_k/2)
cos = self.cos_cached[token_positions]
sin = self.sin_cached[token_positions]
# 2. 维度对齐
# 只有当 x 是 4D (含 Head 维) 且 cos 是 3D (含 Batch 维) 时, 才需要手动插入 Head 维。
# 对于 test_rope 这种 3D x vs 2D cos 的情况, PyTorch 会自动左侧补 1, 无需操作。
if x.ndim > cos.ndim and cos.ndim >= 3:
cos = cos.unsqueeze(1)
sin = sin.unsqueeze(1)
# 确保类型一致
cos = cos.to(x.dtype)
sin = sin.to(x.dtype)
# 3. 拆分
x_even = x[..., 0::2]
x_odd = x[..., 1::2]
output = torch.empty_like(x)
output[..., 0::2] = x_even * cos - x_odd * sin
output[..., 1::2] = x_even * sin + x_odd * cos
return output
3. 多头注意力(Multi-Head Attention)
3.1 缩放点积注意力
3.1.1 为什么
Attention的核心思想是让模型关注输入中重要的部分,忽略不重要的部分。
3.1.2 是什么
给定 Q, K, V(形状均为 (B, n_heads, T, d_k)),计算公式为:
mask为可选的因果掩码(下三角),防止看到未来信息。Q、K、V 本质上就是三个可学习的线性投影矩阵对输入X的变换结果。
它们没有“提问”、“匹配”这种内在属性,只是优化算法通过梯度下降,在训练数据上自动学会了让这三个投影承担不同的统计角色(query key value)。
3.1.3 公式深入
softmax :
将离散数值转换为概率表示(针对特定的轴)。:
由前面的softmax公式可以看出,如果方差过大的话,小值会被稀释掉,并且softmax可能陷入“一家独大”的情况,所以除以可以减少方差来减缓这种影响。mask:
我们训练的目的是为了让模型预测下一个值,而训练数据本身是完整的段落,如果不加mask模型是可以看到未来的值的,这显然不利于训练。添加mask可以屏蔽未来的值对模型的影响。
3.1.4 代码实现
def scaled_dot_product_attention(
Q: torch.Tensor,
K: torch.Tensor,
V: torch.Tensor,
mask: torch.Tensor = None
) -> torch.Tensor:
"""
参数:
Q: [..., n, d_k] (n 为查询序列长度)
K: [..., m, d_k] (m 为键值序列长度)
V: [..., m, d_v]
mask: [n, m] 布尔矩阵, True 为保留, False 为屏蔽
"""
d_k = Q.size(-1)
# 1.计算相似度分数 (Scores)
# einsum 语义: 沿着 d_k 维度(k)进行点积, 保留 batch(...)、 query(n) 和 key(m) 维度
# 结果形状: [..., n, m]
scores = torch.einsum('...nk, ...mk -> ...nm', Q, K) / math.sqrt(d_k)
# 2. 应用因果掩码 (Masking)
if mask is not None:
# 将 False 对应位置的分数设为负无穷, 使其在 Softmax 后概率为 0
scores = scores.masked_fill(mask == False, float('-inf'))
# 3. 计算注意力权重 (归一化)
# dim=-1 对应的是每一个 Query 对所有 key 的分布
probs = softmax(scores, dim=-1)
# 4. 加权求和得到输出 (Output)
# enisum 语义: 利用 probs(n, m) 对 V(m, k) 进行加权求和
# 结果形状: [..., n, d_v]
output = torch.einsum('...nm, ...mk -> ...nk', probs, V)
return output
3.2 多头机制
3.2.1 是什么
其实本质上就是将前面embedding后得到的特征维度d_k拆分成多份,分别计算注意力,最终通过线性层合并。
3.2.2 为什么
我们认为这种方式可以看到“不同角度”的特征,在工程上能够取得更好的效果。
3.2.3 维度变化
在代码实现中,最核心的任务是确保张量形状在“拆分”和“合并”过程中完全对齐。
假设输入:
B = 1,S = 4,D = 64,头数 H = 4
则每个头维度 dₖ = 16
3.2.4 代码实现
class CausualSelfAttention(nn.Module):
def __init__(self, d_model: int, num_heads: int, max_seq_len=None, theta=None, device=None, dtype=None):
super().__init__()
# 维度校验
assert d_model % num_heads == 0, "d_model 必须能被 num_heads 整除"
self.d_model = d_model
self.num_heads = num_heads
self.d_k = d_model // num_heads
# 1. Q, K, V 投影层: 将输入映射到三个不同的特征空间
self.q_proj = Linear(d_model, d_model, device=device, dtype=dtype)
self.k_proj = Linear(d_model, d_model, device=device, dtype=dtype)
self.v_proj = Linear(d_model, d_model, device=device, dtype=dtype)
# 2. 输出投影层: 整合所有头的信息
self.output_proj = Linear(d_model, d_model, device=device, dtype=dtype)
# 3.Rope 初始化: 仅在提供 theta 时启用
if theta is not None and max_seq_len is not None:
self.rope = RotaryPositionalEmbedding(theta, self.d_k, max_seq_len, device=device)
else:
self.rope = None
def forward(self, x: torch.Tensor, token_positions: torch.Tensor = None) -> torch.Tensor:
b, s, d = x.shape
# 步骤 1 & 2: 线性投影并拆分多头
# 使用 eniops.rearrange 替代 view + transpose
# 语义: 将长度为 d 的特征维拆成 (h d_k), 并将 h 维移动到序列维 s 之前
q = rearrange(self.q_proj(x), '... s (h d) -> ... h s d', h=self.num_heads)
k = rearrange(self.k_proj(x), '... s (h d) -> ... h s d', h=self.num_heads)
v = rearrange(self.v_proj(x), '... s (h d) -> ... h s d', h=self.num_heads)
# 步骤 3: 应用 RoPE 旋转位置编码
if self.rope is not None:
if token_positions is None:
# 默认生成从 0 开始的顺序位置
# expand 处理 Batch 维度, 不占用额外物理内存
token_positions = torch.arange(s, device=x.device).expand(b, s)
# 对 Q 和 K 进行旋转, V 保持不动
q = self.rope(q, token_positions)
k = self.rope(k, token_positions)
# 步骤 4: 生成因果掩码 (下三角矩阵)
# 确保 Query 只能看到当前及以前的 Key
mask = torch.tril(torch.ones(s, s, device=x.device, dtype=torch.bool))
# 步骤 5: 核心注意力计算 (SDPA)
# 结果形状: (Batch, Heads, Seq, d_k)
attn_out = scaled_dot_product_attention(q, k, v, mask=mask)
# 步骤 6: 合并多头
# 语义: 将多头维度 h 重新并入特征维度
attn_out = rearrange(attn_out, '... h s d -> ... s (h d)')
# 步骤 7: 输出投影
return self.output_proj(attn_out)
4. 前馈网络(FFN)
4.1 为什么
因为注意力计算仅仅负责 “谁跟谁有关”。它是一个线性加权平均操作——把其他位置的 V 向量按权重揉在一起。它擅长“查找”和“聚合”,但不擅长处理“单个向量内部的复杂逻辑”。也就是说,经过注意力计算之后的结果,其实并不能理解自身的含义,而仅仅是理解自身与其他的关系。
4.2 是什么
前馈网络负责的是,对自身信息的理解。通过维度变换的方式,来获取更加高阶的语义信息。
4.3 怎么做
传统的ffn往往是两个线性层组成的,SwiGLU具备更好的性能。
公式:
我们将计算过程拆解为三条路径:
门控分支 (Gate Path):输入x经过 W_1升维,随后应用 SiLU 激活函数。它决定了哪些信息是重要的。
信号分支 (Signal Path):输入 x 经过 W_3 升维。它提供了实际要处理的内容。
融合与降维:将两条路径的结果逐元素相乘(⊗),最后经过W_2映射回原始维度
相比 ReLU,SiLU 在 0 点附近更加平滑,且允许微弱的负值通过,这有助于深层网络中的梯度流动。
4.4 参数规模
传统 FFN:使用 2 个矩阵()。总参数量 。
SwiGLU FFN:使用了 3 个矩阵(升维, 降维)。
如何保持参数量对齐? 为了让 SwiGLU 的总参数量与传统 FFN 持平,我们不再使用 4 倍升维,而是将中间维度 设为 的 8/3 倍。
硬件对齐要求: 为了优化 GPU 计算效率, 通常需要向上取整为 64 的倍数。
4.5 代码实现
def silu_fn(in_features):
# Sigmoid:σ(x) = 1 / (1 + e^{-x})
# SiLU / Swish:x * σ(x)
return in_features * torch.sigmoid(in_features)
class SwigGLU(nn.Module):
def __init__(self, d_model: int, d_ff: int, device=None, dtype= None):
super().__init__()
self.d_ff = d_ff
self.d_model = d_model
# W1 和 W3 是并行升维层: d_model -> d_ff
self.w1 = Linear(d_model, d_ff, device, dtype)
self.w3 = Linear(d_model, d_ff, device, dtype)
# W2 是降维层: d_ff -> d_model
self.w2 = Linear(d_ff, d_model, device, dtype)
def forward(self, x: torch.Tensor) -> torch.Tensor:
gate = silu_fn(self.w1(x))
signal = self.w3(x)
return self.w2(gate * signal)
5. 层归一化与残差连接
5.1 层归一化
5.1.1 是什么
LayerNorm 的目标是将神经网络每一层输出的数值强行"拉回"到标准范围。
作用对象: 将每一个 Token 看作独立个体。在 [B, S, D] 张量中,它针对的是 D(特征维度)。
计算频率: 在一个 Batch 中,独立执行 次归一化计算,有 个 D。
5.1.2 为什么
1.训练得更稳定
现状: LLM 包含上百层 Block。
梯度爆炸: 初始音量为 1,若每层增加 0.1,100 层后 。信号会迅速爆炸(NaN)或消失(0),导致梯度崩溃。
LayerNorm: 在每一层出口安装"自动调音器",强行将输出拉回均值 0、方差 1。确保无论模型多深,能量始终恒定。
2.训练得更快
现状(崎岖地形): 若特征维度尺度不一(如维度 A 范围 0~1000,维度 B 范围 0~1),Loss 空间会形成极度扁平的"深谷"。梯度下降时极易震荡,迫使我们使用极小的学习率。
LayerNorm 方案(平缓盆地): 通过对齐所有维度的尺度,将地形重塑为圆形的"大盆地"。
直觉: 在盆地中,坡度均匀,我们可以放心使用更大的学习率,训练效率显著提升。
5.1.3 怎么做
:一个极小的常数(防止除以 0)。
:可学习参数。允许模型在必要时打破"均值0/方差1"的束缚,自主调节信号的幅度和偏移。
5.1.4 代码实现
class LayerNorm(nn.Module):
def __init__(self, d_model: int, eps: float = 1e-5, device=None, dtype= None):
"""
LayerNorm 的手动实现
与 RMS Norm相比, 它同时处理了均值 (Mean) 和方差 (Variance) 。
"""
super().__init__()
factory_kwargs = {'device': device, 'dtype': dtype}
# 1. 学习参数初始化
# weight (gamma): 缩放参数, 初始化为全 1
self.weight = nn.Parameter(torch.ones(d_model, **factory_kwargs))
# bias (beta): 偏移参数, 初始化为全0
# 这是 LayerNorm 独有的, RMSNorm 通常不使用 bias
self.bias = nn.Parameter(torch.zeros(d_model, **factory_kwargs))
self.eps = eps
def forward(self, x: torch.Tensor) -> torch.Tensor:
# x 形状: (batch_size, sequence_length, d_model)
in_dtype = x.dtype
# 2. 转换为 float32 以确保计算均值和方差时的数值稳定性 (防止溢出)
x_float = x.to(torch.float32)
# 3. 计算均值 (Mean)
# 对最后一个维度 (特征维) 求平均, keepdim=True 用于后续减法广播
# 公式: E[x]
mean = x_float.mean(dim=-1, keepdim=True)
# 4. 计算方差 (Variance)
# 公式: Var(x) = E[(x - E[x])^2]
# 注意: 这里使用 biased variance, 与 PyTorch 官方 nn.LayerNorm 对齐
var = x_float.var(dim=-1, keepdim=True, unbiased=False)
# 5. 归一化(Standardization)
# 减去均值进行“中心化”,除以标准差进行缩放
# 公式:(x - mean) / sqrt(var + eps)
x_normed = (x_float - mean) / torch.sqrt(var + self.eps)
# 6. 应用可学习的增益(weight)和偏置(bias)
# 公式: y = x_normed * gamma + beta
result = x_normed * self.weight + self.bias
# 7. 转回输入时的原始数据类型 (如 bfloat16 或 float16)
return result.to(in_dtype)
5.1.5 RMS
研究发现,传统的LayerNorm“减去均值”的操作对性能影响微乎其微,反而增加了计算复杂度。采用RMS的方式能够在不影响性能的同时,大幅提高计算效率,公式如下:
\epsilon:一个微小的常数(如 1e-5),防止除以 0。
g:一个可学习的增益参数 (Gain),维度与隐藏层 d_{model} 一致。
5.1.6 LayerNorm VS RMS
5.1.7 RMS代码实现
class RMSNorm(nn.Module):
def __init__(self, d_model: int, eps: float = 1e-5, device=None, dtype= None):
super().__init__()
factory_kwargs = {'device': device, 'dtype': dtype}
# 1. 必须初始化为全 1 (ones)
self.weight = nn.Parameter(torch.ones(d_model, **factory_kwargs))
self.eps = eps
def forward(self, x: torch.Tensor) -> torch.Tensor:
# x : (batch_size, sequence_length, d_model)
in_dtype = x.dtype
# 2. 转换为 float32 以确保计算均值和方差时的数值稳定性 (防止溢出)
x_float = x.to(torch.float32)
# 3. 计算均方根 (Root Mean Square)
# 公式: rms = sqrt( mean(x^2) + eps )
# dim=-1 表示在隐藏层维度计算, keepdim=True 方便后续除法自动广播
ms = x_float.pow(2).mean(dim=-1, keepdim=True)
rms = torch.sqrt(ms + self.eps)
# 4. 归一化并乘以可学习的增益函数 g
result = (x_float / rms) * self.weight
# 5. 转回原始类型
return result.to(in_dtype)
5.2 残差连接
5.2.1 为什么
残差连接用于解决梯度消失的问题,是所有深层神经网络能够正常训练的关键。
假设网络有 100 层,每层都有一个很小的系数(比如 0.9)来更新梯度:
梯度要穿越 100 层,每层乘 0.9,100 次方后,传到输入层的梯度就变成了 0.9^{100}≈0。模型根本学不动,这叫梯度消失。
5.2.2 是什么
残差连接的数学形式极其简单,就是对输入和经过变换后的输出做一次加法:
这样,反向传播公式变为:
这意味着,无论 F(x)的梯度变得多小,梯度至少还有1能够直接无损地传回输入层。这就确保了底层的参数永远能被更新到。
5.2.3 代码实现
其实只是做了给加法操作:
# 注意力子层后的残差
x = x + self.attn(self.norm1(x))
# 前馈子层后的残差
x = x + self.ffn(self.norm2(x))
现代 Transformer 多采用 Pre‑LayerNorm(先归一化,再经过子层),更稳定:
# 注意力块
x = x + self.attn(self.norm1(x))
# 前馈块
x = x + self.ffn(self.norm2(x))
6. 完整的 Decoder 块
class TransformerBlock(nn.Module):
def __init__(self, d_model: int, num_heads: int, d_ff: int, max_seq_len: int,
theta: float, device=None, dtype=None):
super().__init__()
# 初始化因果自注意力模块
self.attn = CausualSelfAttention(
d_model=d_model,
num_heads=num_heads,
max_seq_len=max_seq_len,
theta=theta,
device=device,
dtype=dtype
)
# 初始化两个 RMSNorm 层, 分别服务于 Attention 和 FFN
self.ln1 = RMSNorm(d_model, device=device, dtype=dtype)
self.ln2 = RMSNorm(d_model, device=device, dtype=dtype)
# 初始化前馈网络 (SwiGLU)
self.ffn = SwigGLU(d_model, d_ff, device=device, dtype=dtype)
def forward(self, x: torch.Tensor, token_positions: torch.Tensor = None) -> torch.Tensor:
# 步骤 1: Attention 子层 (Pre-norm 结构)
# x 被分成两路: 一路直接传走 (残差), 一路进 Norm+Attention
x = x + self.attn(self.ln1(x), token_positions=token_positions)
# 步骤 2: FFN 子层 (Pre-norm 结构)
# 再次分流: 一路直接传走, 一路进 Norm+FFN
x = x + self.ffn(self.ln2(x))
return x
7. 整体模型
# 代码参考:[4.2 完整语言模型架构的组装 - 飞书云文档](https://mcn1qim8uhqh.feishu.cn/wiki/SX6swGd6kisMKZkS5cZcXDWBnFb)
class TransformerLM(nn.Module):
def __init__(self, vocab_size: int, max_seq_len: int, d_model: int,
num_layers: int, num_heads: int, d_ff: int, rope_theta: float,
device=None, dtype=None,
# 新增实验参数
use_rms_norm: bool = True,
norm_mode: str = "pre",
ffn_type: str = "swiglu"):
super().__init__()
self.max_seq_len = max_seq_len
self.context_length = max_seq_len
# 1. Token Embedding 层
self.token_embeddings = Embedding(vocab_size, d_model, device=device, dtype=dtype)
# 2. 堆叠 Transformer Blocks
# 将实验参数透传给每一个 Block
self.layers = nn.ModuleList([
TransformerBlock(
d_model, num_heads, d_ff, max_seq_len, rope_theta,
device=device,dtype=dtype,
# use_rms_norm=use_rms_norm,
# norm_mode=norm_mode,
# ffn_type=ffn_type
)
for _ in range(num_layers)
])
# 3. 最终的输出层
# 如果全局禁用了 Norm, 这里的 Final Norm 也要变成 Identity
if use_rms_norm:
self.ln_final = RMSNorm(d_model, device=device, dtype=dtype)
else:
"""
forward(input):
return input
"""
self.ln_final = nn.Identity()
# 最后是一个 Linear 层映射回词表大小 (LM Head)
self.lm_head = Linear(d_model, vocab_size, device=device, dtype=dtype)
def forward(self, token_ids: torch.Tensor) -> torch.Tensor:
b, s = token_ids.shape
# 准备位置信息用于 RoPE, shape: [S] -> [1, S] -> [B, S]
token_positions = torch.arange(s, device=token_ids.device).unsqueeze(0).expand(b, s)
# 1. Embedding
x = self.token_embeddings(token_ids)
# 2. 逐层通过 Transformer Blocks
for layer in self.layers:
x = layer(x, token_positions=token_positions)
# 3. 最终归一化 (如果 use_rms_norm=False, 这里就是直通)
x = self.ln_final(x)
# 4. 投影到词表空间得到 logits
return self.lm_head(x)
@torch.no_grad()
def generate(
self,
prompt_ids: torch.Tensor,
max_new_tokens: int,
eos_token_id: int = None,
temperature: float = 1.0,
top_p: float = 1.0
) -> torch.Tensor:
"""
从模型生成文本 ID 序列。
参数:
prompt_ids: 提示词 ID (Batch, Seq_len)
max_new_tokens: 最多生成的词数
eos_token_id: 停止生成的 Token ID (如 <|endoftext|>)
temperature: 温度系数 (越高越随机, 越低越稳定)
top_p: 核采样阈值
"""
# 设置为评估模式
self.eval()
# 将输入拷贝一份, 避免修改原始数据
generated = prompt_ids.clone()
for _ in range(max_new_tokens):
# 1. 裁剪输入: 模型只能处理 context_length 长度的内容
# 如果生成的序列过长, 只取最后的 context_length 个词
idx_cond = generated[:,-self.context_length:]
# 2. 前向传播得到 Logits
# 我们只关心最后一个时间步的预测
logits = self.forward(idx_cond) # (Batch, T, Vocab)
logits = logits[:, -1, :] # (Batch, Vocab)
# 3. 应用温度 (Temperature)
if temperature != 1.0:
logits = logits / (temperature + 1e-8) # 加个 epsilon 防止除以 0
# 4. 应用 Top-P (Nucleus Sampling) 过滤
if top_p < 1.0:
logits = self._top_p_filter(logits, top_p)
# 5. 归一化并采样
probs = softmax(logits, dim=-1)
next_token = torch.multinomial(probs, num_samples=1) # (Batch, 1)
# 6. 拼接新词
generated = torch.cat((generated, next_token), dim=1)
# 7. 如果遇到了 EOS, 提前结束生成
if eos_token_id is not None and (next_token == eos_token_id).all():
break
return generated
def _top_p_filter(self, logits: torch.Tensor, p: float) -> torch.Tensor:
"""内部工具函数: 执行 Top-P 截断"""
# 对词表分值进行降序排序
sorted_logits, sorted_indices = torch.sort(logits, descending=True, dim=-1)
# 计算累计概率分布
cumulative_probs = torch.cumsum(softmax(sorted_logits, dim=-1), dim=-1)
# 创建掩码: 我们要去掉累计概率超过 p 的 Token
# 逻辑: 保留最小的集合 V(p), 使其概率之和 >= p
# 我们把所有超过 p 的位置标记为 True (需要移除)
sorted_indices_to_remove = cumulative_probs > p
# 关键修正: 确保至少保留第一个词 (最高概率词),
# 并且我们要保留第一个"使概率超过 p" 的那个词。
# 做法是把标记位向右移动一格。
sorted_indices_to_remove[..., 1:] = sorted_indices_to_remove[..., :-1].clone()
sorted_indices_to_remove[..., 0] = False
# 将被移除的 Token 分数设为负无穷
# 这里需要利用 scatter 将排序后的掩码映射回原始词表索引位置
indices_to_remove = sorted_indices_to_remove.scatter(1, sorted_indices, sorted_indices_to_remove)
logits = logits.masked_fill(indices_to_remove, float('-inf'))
return logits
8. 小结
Transformer 的核心是 自注意力 + 前馈网络,配合残差连接与层归一化。
位置信息通过 RoPE 在注意力内部注入。
多层的堆叠赋予了模型学习复杂模式的能力。
训练时还需要 优化器、学习率调度 和 损失函数(见后续文章)。





