
Transformer训练组件
1. 交叉熵损失函数(Cross-Entropy Loss)
1.1 为什么
模型最终输出是形如的一个张量,再经过激活函数,代表了每个 ID 对应的概率。而真实标签 存储的是标准答案的索引ID。
因此,交叉熵的目标是使得正确 ID 对应的 分值尽可能高,其他词的分值尽可能低。
1.2 是什么
对于某个位置的输出 和正确索引 ,损失 的标准定义为:
显然除法操作在工程上是比较复杂的,因此可以做工程化拆解:
利用,我们可以将公式展开:
1.3 LogSumExp
1.3.1 公式
利用恒等式:。
其中 。
1.3.2 公式推导
1.3.3 好处
减去 M 后,o_j - M 的最大值正好是 0。
\exp(0) = 1,这保证了求和项中至少有一个 1,彻底杜绝了分母为 0 的下溢风险。
所有指数项都在 (0, 1] 之间,彻底杜绝了数值爆炸的上溢风险。
1.4 代码实现
def cross_entropy(logits: torch.Tensor, targets: torch.Tensor) -> torch.Tensor:
"""
计算数值稳定的交叉熵损失。
参数:
logits: 形状为 (Batch, Seq, Vocab_size) 的预测分值
targets: 形状为 (Batch, Seq) 的真实 Token ID
"""
# 1. 计算每组 Logits 的最大值 M, 用于数值稳定
# dim=-1 表示在词表维度搜索, keepdim=True 保证结果形状为 (Batch, Seq, 1)
# 这样在后续执行 'logits - m' 时可以触发自动广播
m = torch.max(logits, dim=-1, keepdim=True).values
# 2. 提取目标位置对应的原始分值 o_y
# 使用 gather 函数从词表维度中根据 targets 提取对应的分值
# 由于 gather 要求 index 的维度与输入一致, 需将 targets 升维成 (Batch, Seq, 1)
# 这里 相当于拿着tokenID取出来正确的那个概率。
targets_logits = torch.gather(logits, dim=-1, index=targets.unsqueeze(-1)).squeeze(-1)
# 3. 计算 Log-Sum-Exp 项
# shifted_logits 最大值为 0, exp 运算安全
shifted_logits = logits - m
# 公式: M + log(sum(exp(0 - M)))
# 注意: m 提取出来后形状是 (B, S, 1), 求和项形状是 (B, S), 相加时需先 squeeze m
log_sum_exp = m.squeeze(-1) + torch.log(torch.sum(torch.exp(shifted_logits), dim=-1))
# 4. 计算每个 Token 的独立损失值
# shape:[B,S]
loss = log_sum_exp - targets_logits
# 5.按照作业要求, 对整个批次求平均, 返回一个标量
# loss.backward()
return torch.mean(loss)
2. 优化器(Optimizer)
2.1 优化器的本质:
在训练大模型时,我们的目标是寻找一组参数,使得损失函数 最小。优化器就是更新参数的策略。
输入:当前的梯度 (告诉我们要往哪走)。
状态:历史的信息。
输出:下一步的参数 。
所有优化器干的就是同一件事——决定“怎么把当前算出来的梯度(g_t)换算成模型参数的更新量(Δθ)”。
2.2 优化器的历史演变
2.2.1 SGD (随机梯度下降):只看当下的"鲁莽汉"
最基础的更新策略,没有任何记忆,完全依赖当前的梯度。
公式:
:学习率(步长)。
:当前时刻的梯度。
痛点:
遇到峡谷(震荡):如果梯度方向变化剧烈(比如在一个狭长的山谷里),SGD 会在两壁之间反复横跳,收敛极慢。
遇到平原(停滞):如果梯度很小(鞍点),更新量 会趋近于 0,模型走不动了。
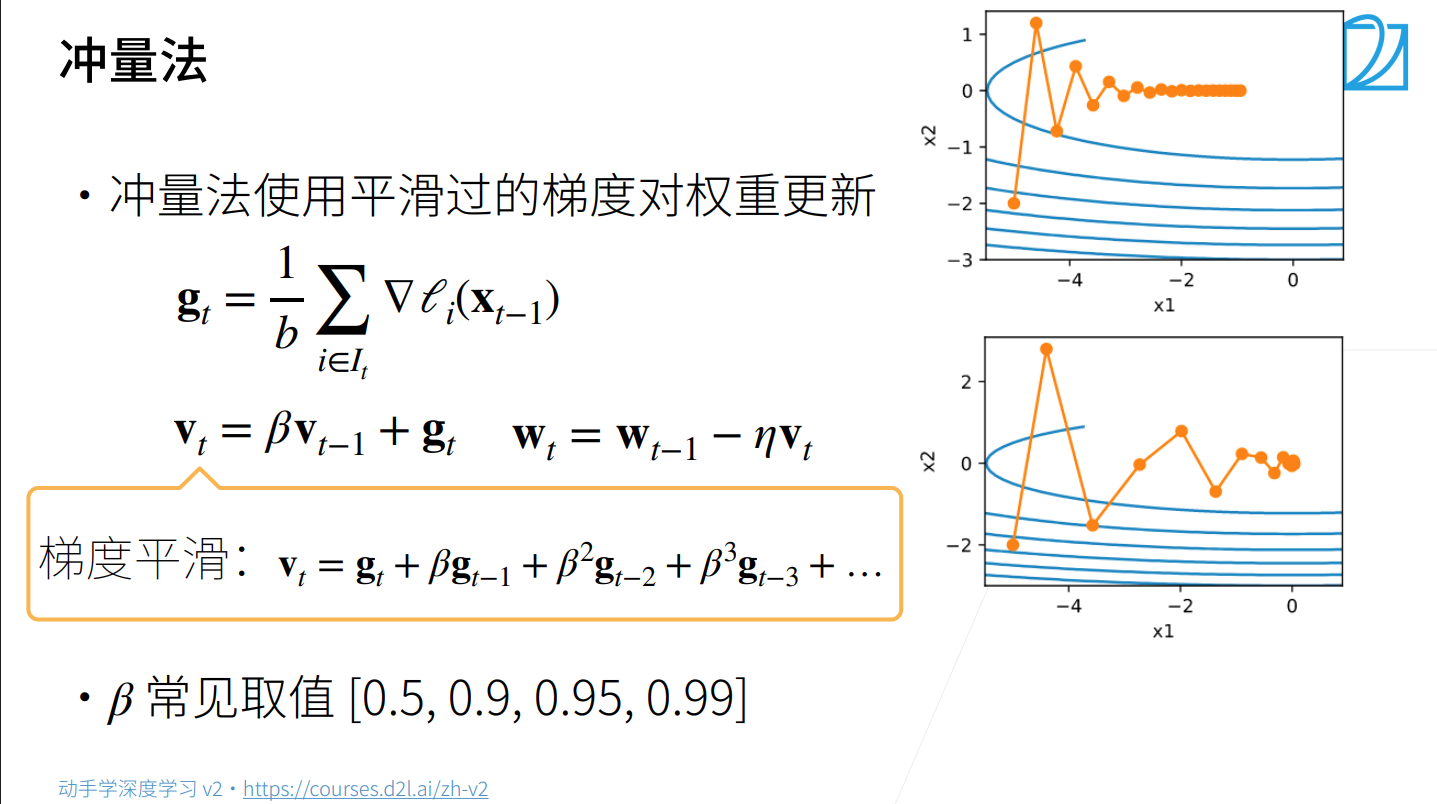
2.2.2 Momentum (动量法):引入惯性的"铁球"
为了解决震荡,我们模拟物理世界中的动量。让参数更新不仅仅依赖当前梯度,还保留一部分之前的速度。
公式:
:一阶动量(梯度的指数移动平均)。
:摩擦系数(通常 0.9)。意味着我们保留 90% 的历史速度,只听 10% 的当前指挥。
进化点:
冲过平原(局部最优解):即使当前梯度 g_t 为 0,靠着历史惯性 m_{t-1},球还能继续滚。
抑制震荡:震荡方向的梯度正负相消,而主路方向的梯度不断累积,速度越来越快。
2.2.3 RMSProp (均方根传播):自带路况适应的"越野车"
Momentum 解决了方向问题,但没解决步长问题。我们希望:在陡峭的地方步子小点(防炸),在平坦的地方步子大点(提速)。
公式:
:二阶动量(梯度平方的移动平均,反映了梯度的"能量"或"波动程度")。
:自适应缩放系数。梯度越大,分母越大,步长越小(自动刹车);梯度越小,步长越大(自动加油)。
进化点:实现了参数级的自适应学习率。不同的参数可以有不同的更新速度。
2.2.4 Adam (Adaptive Moment Estimation):集大成者
Adam 是 Momentum 和 RMSProp 的结合体,它既有惯性(一阶矩),又有自适应步长(二阶矩),并加入了偏差修正。
完整流程公式:
a. 算一阶矩(方向):
b. 算二阶矩(力度):
c. 偏差修正(解决冷启动):
更新参数:
2.3 AdamW
Adam 看起来已经完美了,但在很长一段时间里,它在 CV 和 NLP 的最终泛化能力上都不如 SGD + Momentum。直到 2017 年,人们发现 Adam 在处理权重衰减 (Weight Decay) 时存在严重的逻辑错误。
1. L2 正则化 vs. 权重衰减
在 SGD 中,这两者是等价的。
L2 正则:在 Loss 后加一项 。
求导后:梯度变成了 。
SGD 更新:
可以看到,L2 正则化最终导出了权重衰减项。
2. Adam 的"耦合"灾难
如果我们把 L2 正则化()直接塞进 Adam 的更新公式里,会发生什么?
注意分母上的。
实际的衰减力度变成了 。
后果:
当 很大时(梯度变化剧烈,比如陡峭区域):分母大,衰减力度变小了。这很不合理! 梯度大的参数往往数值也大,恰恰需要更强的正则化来抑制过拟合,Adam 却反而保护了它。
当 很小时(平坦区域):分母小,衰减力度变大了。可能会误杀重要的细微特征。
这种"衰减力度受梯度假释"的现象,就是所谓的耦合(Coupled)。
3. AdamW:解耦(Decoupled)的正确姿势
AdamW 的核心思想是:让权重衰减独立于梯度更新,单独执行。
AdamW 更新公式:
a. 先按标准的 Adam 计算梯度步长:
b. 独立执行衰减:
结论:在 AdamW 中,无论地形(v_t)如何,每个参数每一步都要雷打不动地向 0 收缩固定的比例()。这种一致性让大模型的训练更稳定,泛化能力更强。
2.4 权重衰减
在大模型(LLM)预训练中,权重衰减是必须开启的,原因有三点:
防止过拟合
如果权重非常大,模型就会变得非常"敏感"。输入里的一丁点噪声,经过大权重的放大,都会导致输出剧变。这说明模型在"死记硬背"训练数据。
权重衰减强迫模型用更小的权重去解决问题,从而逼模型去学习普适的规律,而不是记住噪音。提高数值稳定性
大模型有上百层。如果每一层的权重都很大,信号在传递过程中会指数级膨胀,最终导致 NaN(数值溢出)。
权重衰减就像是一个"限压阀",把参数控制在温和的范围内,保住模型的命。增加泛化能力
根据奥卡姆剃刀原理:如果两个模型都能解释数据,我们倾向于选择更简单的那个。
权重更小的模型,在数学上等价于更简单的函数。这让模型在面对从未见过的测试数据时,表现更稳。
2.5 代码实现
class AdamW(Optimizer):
def __init__(self, params, lr=1e-3, betas=(0.9, 0.999), eps=1e-8, weight_decay=0.01):
# 1. 基本参数检查
if lr < 0.0:
raise ValueError(f"Invalid Learning rate: {lr}")
if not 0.0 <= betas[0] < 1.0:
raise ValueError(f"Invalid beta parameter at index 0: {betas[0]}")
if not 0.0 <= betas[1] < 1.0:
raise ValueError(f"Invalid beta parameter at index 1: {betas[1]}")
if eps < 0.0:
raise ValueError(f"Invalid epsilon value: {eps}")
# 2. 将超参数存入 defaults 字典
defaults = dict(lr=lr, betas=betas, eps=eps, weight_decay=weight_decay)
super().__init__(params, defaults)
@torch.no_grad()
def step(self):
"""执行单步优化更新"""
loss = None # loss 只是走个形式,并无实际意义,参考了pytorch官方的写法
for group in self.param_groups:
beta1, beta2 = group['betas']
eps = group['eps']
lr = group['lr']
wd = group['weight_decay']
for p in group['params']:
if p.grad is None:
continue
grad = p.grad
state = self.state[p]
# 3. 状态初始化 (第一次运行步时执行)
if len(state) == 0:
state['step'] = 0
# m: 一阶矩 (梯度的指数移动平均)
state['exp_avg'] = torch.zeros_like(p, memory_format=torch.preserve_format)
# v: 二阶矩 (梯度平方的指数移动平均)
state['exp_avg_sq'] = torch.zeros_like(p, memory_format=torch.preserve_format)
exp_avg, exp_avg_sq = state['exp_avg'], state['exp_avg_sq']
state['step'] += 1
t = state['step']
# 4. 更新矩估计 (Algorithm 1)
# m = beta1 * m + (1 - beta1) * g
exp_avg.mul_(beta1).add_(grad, alpha=1 - beta1)
# v = betas * v + (1 - beta2) * g^2
exp_avg_sq.mul_(beta2).addcmul_(grad, grad, value=1 - beta2)
# 5. 计算偏差校正后的学习率 alpha_t
# 这一步是为了消除初始值为 0 带来的偏移
bias_correction1 = 1 - beta1 ** t
bias_correction2 = 1 - beta2 ** t
step_size = lr * (math.sqrt(bias_correction2) / bias_correction1)
# 6. 更新参数: theat = theta - alpha_t * m / (sqrt(v) + eps)
denom = exp_avg_sq.sqrt().add(eps)
# 这是一个专门为优化器设计的符合算子, 名字可以拆解为: add(加) + constant (常数) + div (除)。
# p.addcdiv_(tensor1, tensor2, value=1.0)。 p=p+valuex( tensor1 / tensor2 )
p.addcdiv_(exp_avg, denom, value=-step_size)
# 7. 应用解耦的权重衰减 (AdamW 的核心特性)
# theta = theta - alpha * lambad * theta
# p.add_(other, alpha=1.0) p=p+(alohaxother)
if wd != 0:
p.add_(p, alpha=-lr * wd)
return loss
3. 学习率调度(Learning rate scheduling)
3.1 为什么
如果我们在整个训练过程中使用固定的学习率,模型会面临两个困境:
起步难:训练初期,模型参数是随机初始化的。如果学习率过大,不稳定的梯度会瞬间破坏模型,导致 Loss 爆炸。
收敛难:训练后期,模型已经接近最优解。如果学习率依然很大,优化器会在"山谷"底部反复横跳,无法进入最精确的低点。
解决方案:
Warmup(预热):起步时,学习率从 0 线性增加到最大值。
Cosine Decay(余弦衰减):到达顶点后,学习率按照余弦曲线平滑下降。
3.2 怎么做
3.2.1 预热阶段 (Warm-up)
逻辑:像飞机起飞,在跑道上逐渐加速。
公式:
物理意义:让模型在不稳定的训练初期,以极小的步长"试探"方向,逐渐过渡到高速训练。
3.2.2 余弦退火阶段 (Cosine Annealing)
逻辑:像平滑降落,优雅地进入最优区域。
公式核心:利用 cos 函数在 [0, \pi] 区间从 1 降到 -1 的特性。
通过,我们将波动范围映射到 [1, 0]。
优势:相比于阶梯式下降,余弦退火没有突然的数值跳变,梯度更加平滑。
3.2.3 退火后阶段 (Post-annealing)
逻辑:保持最低速滑行。
公式:
物理意义:当预定的训练周期结束,如果还需要继续训练,则维持一个极小的学习率进行微调。
3.2.4 拓展链接
zhuanlan.zhihu.com/p/14402471296
3.3 代码实现
def get_lr_cosine_schedule(
it: int,
max_learning_rate: float,
min_learning_rate: float,
warmup_iters: int,
cosine_cycle_iters: int
) -> float:
"""
计算第 it 次迭代时, 带预热的余弦退火学习率。
参数:
it: 当前迭代步数 (t)
max_learning_rate: 学习率的峰值 (alpha_max)
min_learning_rate: 学习率的底值 (alpha_min)
warmup_iters: 预热阶段的总步数 (T_w)
cosine_cycle_iters: 整个衰减周期结束的步数 (T_c)
"""
# 1. 预热阶段: 线性增长周期
if it < warmup_iters:
# 从 0 匀速增长到 max_learning_rate
return max_learning_rate * it / warmup_iters
# 2. 衰减周期后: 维持最小值
if it > cosine_cycle_iters:
return min_learning_rate
# 3. 余弦退火核心逻辑
# a. 计算当前处于退火阶段的进度百分比 (0.0 到 1.0)
# it - warmup_iters: 距离预热结束走了多少步
# cosine_cycle_iters - warmup_iters: 整个退火阶段的总长度
decay_ratio = (it - warmup_iters) / (cosine_cycle_iters - warmup_iters)
# b. 计算余弦系数
# math.cos(math.pi * decay_ratio):
# 当前进度为 0 时, 结果为 cos(0) = 1
# 当前进度为 1 时, 结果为 cos(pi) = -1
# coeff = 0.5 * (1 + [-1, 1]) -> 范围 [0.0, 1.0]
coeff = 0.5 * (1.0 + math.cos(math.pi * decay_ratio))
# c. 最终计算
# 学习率从 max 降向 min
return min_learning_rate + coeff * (max_learning_rate - min_learning_rate)
4. 梯度裁剪
4.1 为什么
在训练深层 Transformer 模型时,由于网络层数多且包含复杂的非线性变换,模型经常会遇到梯度爆炸的问题。本节我们将实现梯度裁剪,确保模型在不稳定的训练初期或遇到极端数据时不会崩溃。
4.2 怎么做
在每次反向传播之后、优化器步进(Step)之前,检查所有参数梯度的总长度(Global Norm)。如果总长度超过了安全阈值 M,它就把你的步子按比例收回来,确保你的步长在安全范围内,但保持前进的方向不变。
4.3 数学原理
梯度裁剪的核心是计算全局 L2 范数。我们将模型中所有层的梯度拼接成一个巨大的向量 g,然后计算它的欧几里得长度:
如果 |g|_2 > M,则对所有梯度进行等比例缩放:
4.4 代码实现
def clip_gradient_norm(parameters: Iterable[torch.nn.Parameter], max_norm: float):
"""
实现全局梯度裁剪(Global Norm Clipping)。
参数:
parameters: 模型的所有参数 (model.parameters())
max_norm: 允许的最大梯度 L2 范数 (M)
"""
# 1. 过滤掉没有梯度的参数 (防止对 None 对象操作)
params_with_grad = [p for p in parameters if p.grad is not None]
if not params_with_grad:
return
# 2. 计算全局 L2 范数 (Global L2 Norm)
total_norm = 0.0
for p in params_with_grad:
# 使用 .detach() 极其重要:
# 梯度裁剪是在计算完导数后进行的数值操作, 我们不希望“计算范数”的过程也被记入计算图。
# torch.norm(..., p=2) 算出当前层梯度的 L2 范数 L_i
param_norm = torch.norm(p.grad.detach(), p=2)
# 将各层范数的平方累加 (L_total = sqrt(sum(L_i^2)))
total_norm += param_norm.item() ** 2
total_norm = total_norm ** 0.5
# 3. 检查是否触发裁剪
eps = 1e-6 # 防止除零的稳定性常数
if total_norm > max_norm:
# 计算统一的缩放系数
clip_coef = max_norm / (total_norm + eps)
# 4. 原地 (in-place) 修改每个参数的梯度
# 使用 mul_ 直接修改内存, 不产生临时副本, 节省显存
for p in params_with_grad:
p.grad.detach().mul_(clip_coef)
5. 数据加载与批处理(Data Loader)
5.1 训练任务的本质:下一个 Token 预测
语言模型的训练目标是:给定前 m 个词,预测第 m+1 个词。
为了高效训练,在一个长度为 L 的窗口内,我们不仅预测最后一个词,而是让模型在每一个位置都预测它的下一个词。
输入 (x):从索引 i 开始,长度为 L 的序列:。
目标 (y):输入序列向后平移一位,长度同样为 L:。
物理意义:
当模型看到输入中的第一个词 时,它应该输出 ;看到 时,应输出。这种偏移设计允许我们在一个计算步内完成 L 次学习。
5.2 代码实现
def get_batch(
dataset: npt.NDArray,
batch_size: int,
max_seq_length: int,
device: str
) -> tuple[torch.Tensor, torch.Tensor]:
"""
随机采样一个训练批次。
返回:
x: 输入张量, 形状 [batch_size, max_seq_length]
y: 目标张量, 形状 [batch_size, max_seq_length]
"""
n = len(dataset)
# 最后一个可用的起点, 必须流出 max_seq_length 的空间给 x, 再多留 1 位给 y
max_idx = n - max_seq_length - 1
# 随机选择 batch_size 个起始点
ix = torch.randint(0, max_idx + 1, (batch_size,))
# 提取序列并转为 Numpy 数组, 再转为 Tensor
# 这样做比循环里逐个 to(device) 快得多
x = torch.stack([torch.from_numpy(dataset[i : i + max_seq_length].astype(np.int64)) for i in ix])
y = torch.stack([torch.from_numpy(dataset[i+1 : i + max_seq_length + 1].astype(np.int64)) for i in ix])
# 一次性搬运到 GPU
return x.to(device) , y.to(device)
5.3 代码详解
由于数据集通常极大(几百 GB),我们不能使用传统的 list。代码基于 Numpy 数组(通常配合内存映射 mmap 使用)进行操作。
5.3.1 确定合法边界
max_idx = n - max_seq_length - 1
为什么要减 1? 因为目标序列 y 需要取到 i + L + 1 的位置。如果不减 1,当随机抽到序列末尾时,取 y 会发生越界错误。
5.3.2 随机采样起始点
ix = torch.randint(0, max_idx + 1, (batch_size,))
逻辑:一次性生成
batch_size个随机数,作为本批次中每个句子的"起点"。这种随机性保证了模型每一轮看到的组合都不一样,有利于泛化。
5.3.3 内存切片与堆叠
x_stack = [dataset[i : i + max_seq_length] for i in ix]
y_stack = [dataset[i + 1 : i + max_seq_length + 1] for i in ix]
逻辑:利用 Python 列表推导式从 Numpy 数组中提取片段。此时数据仍在 CPU 内存中。
5.3.4 张量化与类型转换
x = torch.from_numpy(np.array(x_stack)).to(device).long()
类型转换:原始数据通常是
uint16或int32,但 PyTorch 的 Embedding 层要求输入必须是int64(Long)。因此显式调用.long()是防止报错的关键。
5.3.5 内存映射 (np.memmap)
这是大模型训练的标配技术。
在 main_train.py 中,你不会直接 f.read() 整个文件,而是使用:
# 训练脚本中的典型用法
data = np.memmap('train.bin', dtype=np.uint16, mode='r')
原理:
memmap并不真正把数据读入 RAM,而是在磁盘和逻辑内存间建立映射。配合 get_batch:当
get_batch执行切片操作时,操作系统才会去磁盘上精确地把那几 KB 的数据拉进缓存。价值:这让你能在只有 16GB 内存的个人电脑上,轻松训练存储在 500GB 硬盘里的数据集。
6.模型保存与恢复(CheckPoint)
6.1 为什么?
容错性:当训练意外中断时,可以从最近的存档点恢复,而不是从第 0 步重头开始。
恢复优化器状态:最容易忽略的一点。像 AdamW 这样有状态的优化器,内部记录了每个参数的动量(m)和平方梯度(v)。如果只恢复模型权重而不恢复优化器状态,训练会产生巨大的数值冲击,导致 Loss 剧烈震荡甚至爆炸。
断点续训:通过记录
iteration(迭代步数),可以确保学习率调度器 (Scheduler) 从正确的时间点继续执行余弦退火。
6.2 state_dict
在 PyTorch 中,无论是模型(nn.Module)还是优化器(Optimizer),其核心状态都存储在 state_dict 中。
它是一个标准的 Python 字典。
模型字典:将每一层的名称(如
layers.0.attn.q_proj.weight)映射到对应的参数张量。优化器字典:记录了当前所有参数的动量信息和步数。
6.3 代码实现
def save_checkpoint(
model: torch.nn.modules,
optimizer: torch.optim.Optimizer,
iteration: int,
out: typing.Union[str, os.PathLike, typing.BinaryIO, typing.IO[bytes]] # 说明 out 参数可以接受以下任意一种类型
):
"""
保存当前训练状态
"""
# 1. 构建一个包含所有必要信息的字典
checkpoint = {
'model_state_dict': model.state_dict(),
'optimizer_state_dict': optimizer.state_dict(),
'iteration': iteration
}
# 2. 使用 torch.save 将字典写入目标 (可以是路径或文件流)
torch.save(checkpoint, out)
def load_checkpoint(
src: typing.Union[str, os.PathLike, typing.BinaryIO, typing.IO[bytes]],
model: torch.nn.Module,
optimizer: torch.optim.Optimizer
)-> int:
"""
从检查点恢复状态, 并返回保存时的迭代次数
"""
# 1. 加载字典
# 使用 map_location='cpu' 可以防止在没有 GPU 的机器上加载时报错
checkpoint = torch.load(src, map_location='cpu')
# 2. 恢复模型权重
model.load_state_dict(checkpoint['model_state_dict'])
# 3. 恢复优化器状态 (动量、步数等)
optimizer.load_state_dict(checkpoint['optimizer_state_dict'])
# 4. 返回保存时的迭代次数
return checkpoint['iteration']
7. 完整训练
7.1 训练流程
同步进度:根据当前步数计算对应的学习率(Cosine Schedule)。
准备数据:从内存映射文件(memmap)中随机采样一个批次(Batch)。
前向传播:计算 Logits,并通过交叉熵函数算出损失(Loss)。
清理现场:清空优化器中上一轮残余的梯度。
反向传播:计算当前参数的梯度。
安全控制:执行梯度裁剪(Gradient Clipping),防止权重更新过猛。
参数更新:优化器根据梯度修改模型权重。
状态监控:定期在验证集上跑分,并将结果记录到云端(WandB)。
7.2 训练代码
import argparse
import os
import torch
import numpy as np
import wandb
from cs336_basics.Layers import TransformerLM
from cs336_basics.criterion import AdamW, clip_gradient_norm
from cs336_basics.criterion import get_lr_cosine_schedule
from cs336_basics.criterion import get_batch
from cs336_basics.criterion import save_checkpoint, load_checkpoint
from cs336_basics.criterion import cross_entropy
def main():
parser = argparse.ArgumentParser()
# --- 模型基础超参数 ---
parser.add_argument("--batch_size", type=int, default=32)
parser.add_argument("--context_length", type=int, default=256)
parser.add_argument("--d_model", type=int, default=512)
parser.add_argument("--num_layers", type=int, default=4)
parser.add_argument("--num_heads", type=int, default=8)
parser.add_argument("--d_ff", type=int, default=2048)
parser.add_argument("--vocab_size", type=int, default=10000)
# --- 实验/消融 (Ablation) 开关 ---
# Ablation 1: 移除 RMSNorm
parser.add_argument("--no_rms_norm", action="store_true", help="Disable RMSNorm completely")
# Ablation 2: Pre-norm vs Post-norm
parser.add_argument("--norm_mode", type=str, default="pre", choices=["pre", "post"], help="Normalization placement")
# Ablation 3: 移除 RoPE (NoPE)
parser.add_argument("--no_rope", action="store_true", help="Disable Rotary Positional Embeddings")
# Ablation 4: SwiGLU vs SiLU
parser.add_argument("--ffn_type", type=str, default="swiglu", choices=["swiglu", "silu"], help="Type of Feed-Forward Network")
# --- 优化器超参数 ---
parser.add_argument("--lr", type=float, default=6e-4)
parser.add_argument("--max_iters", type=int, default=10000)
parser.add_argument("--warmup_iters", type=int, default=1000)
parser.add_argument("--min_lr", type=float, default=6e-5)
parser.add_argument("--max_norm", type=float, default=1.0)
# --- 路径与系统
parser.add_argument("--train_data_path", type=str, required=True)
parser.add_argument("--valid_data_path", type=str, required=True)
parser.add_argument("--out_dir", type=str, default="out")
parser.add_argument("--device", type=str, default="cuda" if torch.cuda.is_available() else "cpu")
# --- WandB 设置 ---
parser.add_argument("--run_name", type=str, default=None, help="WandB 实验名称")
args = parser.parse_args()
os.makedirs(args.out_dir, exist_ok=True)
# 1. 加载数据 (使用 memmap)
# 假设数据是以 uint16 存储的二进制文件
if not os.path.exists(args.train_data_path):
raise FileNotFoundError(f"Training data not found at {args.train_data_path}")
if not os.path.exists(args.valid_data_path):
raise FileNotFoundError(f"Validation data not found at {args.valid_data_path}")
# np.memmap 延迟加载数据到内存, 非常适合大数据集, 并且将二进制文件转为 dtype (uint16) 数组
train_data = np.memmap(args.train_data_path, dtype=np.uint16, mode='r')
val_data = np.memmap(args.valid_data_path, dtype=np.uint16, mode='r')
print(f"训练集大小: {len(train_data)} tokens")
print(f"验证集大小: {len(val_data)} tokens")
# 2. 处理消融实验逻辑
# 如果 no_rope 为 True, 则 theta 设为 None, TransformerBlock 内部就不会初始化 RoPE
actual_rope_theta = None if args.no_rope else 10000.0
# use_rms_norm 逻辑取反
use_rms_norm = not args.no_rms_norm
# 3. 初始化模型
model = TransformerLM(
vocab_size=args.vocab_size,
context_length=args.context_length,
d_model=args.d_model,
num_layers=args.num_layers,
num_heads=args.num_heads,
d_ff=args.d_ff,
rope_theta=actual_rope_theta,
device=args.device,
# 传入实验参数
use_rms_norm=use_rms_norm,
norm_mode=args.norm_mode,
ffn_type=args.ffn_type
).to(args.device)
print(f"Model Config: Norm={args.norm_mode}, UseNorm={use_rms_norm}, FFN={args.ffn_type}, RoPE={not args.no_rope}")
# 4. 初始化优化器
optimizer = AdamW(model.parameters(), lr=args.lr, weight_decay=0.1)
# 5. 检查点恢复逻辑
start_iter = 0
ckpt_path = os.path.join(args.out_dir, "ckpt.pt")
if os.path.exists(ckpt_path):
start_iter = load_checkpoint(ckpt_path, model, optimizer)
print(f"Resuming from iteration {start_iter}")
# 6. 初始化 WandB 监控
wandb.init(
project="cs336-assignment1",
name=args.run_name,
config=args
)
# 7. 主训练循环
for it in range(start_iter, args.max_iters):
# A. 更新学习率
lr = get_lr_cosine_schedule(it, args.lr, args.min_lr, args.warmup_iters, args.max_iters)
for param_group in optimizer.param_groups:
param_group['lr'] = lr
# B. 训练步
model.train()
x, y = get_batch(train_data, args.batch_size, args.context_length, args.device)
logits = model(x)
loss = cross_entropy(logits, y)
optimizer.zero_grad()
loss.backward()
# 梯度裁剪
clip_gradient_norm(model.parameters(), args.max_norm)
optimizer.step()
# C. 验证与日志记录
if it % 100 == 0 or it == args.max_iters - 1:
model.eval()
with torch.no_grad():
vx, vy = get_batch(val_data, args.batch_size, args.context_length, args.device)
v_logits = model(vx)
v_loss = cross_entropy(v_logits, vy)
print(f"Iter {it}: train_loss {loss.item():.4f}, val_loss {v_loss.item():.4f}, lr {lr:.2e}")
wandb.log({
"train/loss": loss.item(),
"val/loss": v_loss.item(),
"lr": lr,
"iter": it + 1
})
# D. 保存检查点 (每 1000 步保存一次)
if it % 1000 == 0 and it > 0:
save_checkpoint(model, optimizer, it, ckpt_path)
# 训练结束保存最终模型
save_checkpoint(model, optimizer, args.max_iters, os.path.join(args.out_dir, "ckpt_final.pt"))
wandb.finish()
if __name__ == "__main__":
main()





